1/28/2026 | 8 Minute Read
Topics:

Server downtime is one of the biggest challenges companies face today, and one of the most preventable. With consistent patch management, monitoring, and maintenance, managed service providers (MSPs) and IT teams can keep businesses operational and secure.
Nearly 60% of data breaches stem from unpatched vulnerabilities, and downtime from failed updates costs small and midsized businesses (SMBs) an average of $10,000–$20,000 per hour in lost productivity and recovery expenses. For MSPs, those numbers highlight just how critical structured processes and reliable patch management software has become for both security and business continuity.
Read on to learn what server patching really entails, how it protects uptime, and the strategies MSPs use to reduce risk while keeping systems running smoothly.
Server patching is an ongoing process that ensures every layer of a server environment, from firmware to operating systems and applications, remains secure and reliable.
Each type has its own risk profile and testing process, and treating them all the same is where most outages begin.
A single failed patch can disrupt business operations instantly. In 2023, a Microsoft update caused boot-loop errors on Windows servers, leaving MSPs restoring from backups for days.
Servers are the backbone of business operations. They store data, deliver critical applications, and process transactions. When they’re up to date, everything flows: applications run smoothly, employees stay productive, and customers enjoy consistent experiences.
But when servers fall behind on patches, serious problems emerge:
Poorly executed patching can also cause outages. A “patch gone wrong” can take systems offline for days if there’s no tested rollback or backup.
The compliance implications are equally significant. Delayed patching can violate frameworks such as HIPAA, PCI DSS, or SOX, exposing organizations to fines and potential loss of certification. Effective patching keeps systems and compliance status secure.
Even the most experienced IT teams face hurdles during patch cycles. Common challenges include:
Overcoming these common patch management challenges requires automation backed by rollback assurance, detailed reporting, and clear governance policies that define ownership across IT and operations.
Every IT team faces the challenge of deploying critical patches while minimizing downtime. The key is combining automation with verification and clear rollback plans.
1. Develop a comprehensive patching strategy: Define how you’ll evaluate patches, when they’ll deploy, and how to recover if something goes wrong. Make roles and communication plans clear across teams.
2. Prioritize critical vulnerabilities: Not all patches are equal. Focus first on those addressing actively exploited vulnerabilities, then move to performance and stability fixes. Use a framework such as the Common Vulnerability Scoring System (CVSS) to guide prioritization.
3. Automate with guardrails: Every automation workflow should map directly to your patch management policy. Automation speeds deployment and ensures consistency, but automation without verification simply spreads problems faster. Pair automated rollouts with pre-patch backup validation and post-patch reporting to confirm stability.
4. Stage and test patches: Pilot patches on low-impact systems first, or use virtual snapshots to identify conflicts before full rollout. Always verify backup recoverability before making changes.
5. Establish failover and rollback mechanisms: Redundancy protects uptime. Whether through load balancing, replicated environments, or business continuity and disaster recovery (BCDR) snapshots, a reliable failover plan ensures operations continue even when updates fail.
6. Schedule maintenance strategically: Plan updates during low-impact windows and communicate with stakeholders ahead of time. Clear expectations prevent frustration when patches require reboots or short service interruptions.
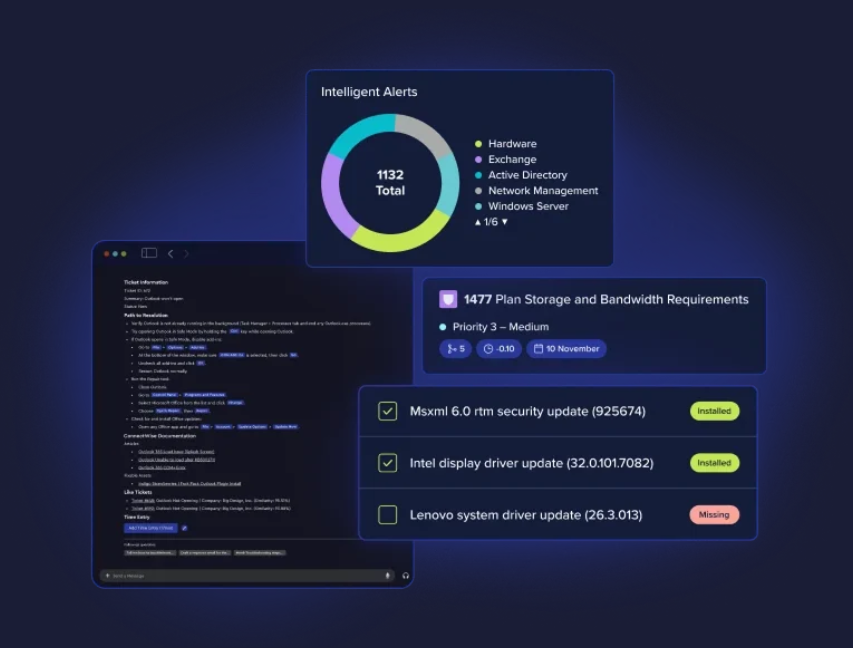
7. Verify and report on patch compliance: Tracking and reporting are as important as deployment. Use your remote monitoring and management (RMM) dashboards to monitor patch success rates, identify high-risk systems, and maintain evidence for compliance or cyber insurance audits. Reporting transparency reinforces trust with clients and auditors alike.
Download our Patch Management Best Practices eBook for more actionable guidance to help you strengthen your patch management strategy.
Unlike single-purpose tools that only automate patch rollout, integrated RMM and BCDR environments provide full rollback assurance and compliance visibility.
ConnectWise delivers automation and visibility through the ConnectWise Platform, helping MSPs patch confidently while protecting uptime:
Together, these tools give MSPs and IT teams the automation they need with the visibility that auditors, insurers, and clients now expect.
Every IT professional knows the rule: Something will break during patching, it’s just a matter of when. The goal isn’t to eliminate risk; it’s to control it.
Automation, recovery validation, and clear visibility turn patching from a 2:00am firefight into a predictable, auditable process that strengthens client trust and keeps systems secure.
Watch an on-demand demo to see how ConnectWise RMM automates patch deployment, validation, and reporting to help you control risk and protect uptime.
Share:


Effective rollback procedures start with pre-patch system snapshots and documented baseline configurations. Many modern servers support automated rollback through built-in recovery tools or virtualization platform snapshots. The key is preparing your rollback procedures before patch deployment and maintaining current system backups just in case.
Server patching should follow formal change management protocols, including pre-approval for critical system updates, documented risk assessments, and stakeholder communication about maintenance windows. Establish an approval workflow based on the patches themselves and their impact on your business. Log, track, and include changes in post-deployment verification.
Start by establishing patch policies, then start measuring how often patches succeed and how quickly critical vulnerabilities are addressed. Also, keep an eye on system uptime after patching. Long downtimes can mean more than just a technical glitch. Document deployment failures and any rollbacks to understand where processes might need improvement.
If your organization is using legacy servers, alternative security strategies are critical. One way to limit exposure is by segmenting these servers to effectively hide them from the rest of your network. Have a strong monitoring system in place, like ConnectWise SIEM and MDR, to catch suspicious activity fast. Planning a migration to a supported platform is another option to consider. When vendor patches aren’t an option, third-party security tools can sometimes help fill the gap.