Are your clients prepared for the next time disaster strikes? No one can predict when the next disruption event may hit your clients’ data centers or IT rooms, but your job as their MSP is to ensure they receive the highest level of preparation and protection possible. Knowing the aspects and importance of recovery time objective vs. recovery point objective, or RTO vs. RPO, is a critical part of that equation.
Occasionally, these two concepts can cause confusion and appear to overlap. Fortunately, the ConnectWise team is here to set the record straight.
In the article below, we’ll be discussing the details of RPO vs. RTO. We’ll define each concept, discuss their fundamental differences, and explain the importance of each metric in your overall disaster recovery plan.
So, read along with us as we demystify the relationship between RTO, RPO, and disaster recovery. There’s a lot of information to cover, so you may want to bookmark this one as a training resource for your clients or staff. Without further ado, let’s get into it.
RTO’s meaning within the IT space is recovery time objective. This metric is the time between the event or disaster responsible for your system failure and the moment the system recovers and returns online. This is a crucial metric to the health of your client’s IT network since, in certain industries, mere seconds offline can result in thousands of dollars in damages.
As an MSP, your job becomes making client RTOs as short as possible. Every second you can shave off a client’s RTO increases their organization’s productivity and reduces the risk of data loss or corruption. In short, as your client’s RTO time shrinks, so does their financial, data, and in some cases, legal risk.
While short RTO times are ideal for every system, some systems are more critical. It’s essential to work with your client to prioritize which systems handle mission-critical data and which systems can afford more extended downtime without much adverse effect.
For example, a network supporting high-frequency securities trades for a hedge fund could lose the company tens of thousands of dollars for every second it’s offline. However, the HR systems for that company could stay down much longer without hurting the organization’s primary business.
Regardless of the system, implementing tools and tactics to improve your RTO costs resources for both you and your client. Whether you’re investing in faster, more complex backup mirroring or even just increasing the speed of your internet, every step toward your client’s target RTO requires an investment of staffing or money. Because of this, achieving optimal RTO on every system within your organization just isn’t a realistic goal. Identify which systems are important and allocate all available resources to giving them the shortest RTO and keeping their downtime at a minimum in the event of a disaster.
RPO’s meaning is recovery point objective. This metric refers to the age of data necessary to recover an IT system in the event of a disaster. When a system failure occurs, MSPs should know how far back a client needs to go to restore their system to normal. Your RPO is the age of the data or files needed to reach this goal. To put it simply, think of RPO as how “fresh” your recovered data needs to be.
Organizations that handle more sensitive data, or a higher volume of transactions, may need more frequent backups than other companies. This is because they need the most current data possible to properly recover their system. The short RPO times companies like these require can be resource intensive.
An organization, like a bank or credit card company, may need almost real-time data to restore its system to pre-incident status. These short RPO times require frequent backups and, as a result, complex or high-speed backup technologies.
Cutting-edge BDR technologies like mirroring can cost companies on several fronts. First, a subscription to the actual BDR tool can be costly. Secondly, running BDR procedures like mirroring or continuous replication may require hiring highly skilled internal employees or high-paid consultants. Third, companies will have to endure the utility cost of the internet bandwidth needed to run these solutions. Companies may feel the weight of these costs even more if their backups are stored off-site in the cloud.
To learn more about how to best prepare your clients for BDR, check out our free eBook: 3 Reasons to Rethink Your BDR Strategy, or contact us with any questions.
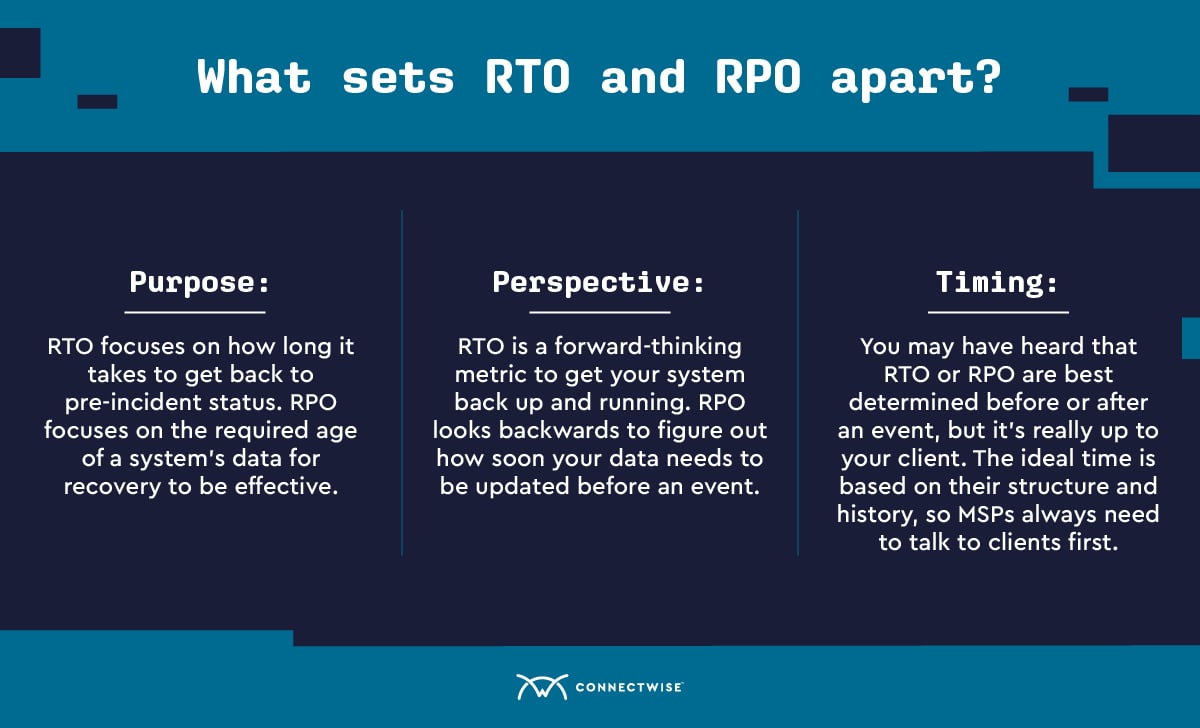
So, what do we need to consider when comparing RTO vs. RPO? Both metrics are important to backup and disaster recovery, but each has individual nuances.
The main differences between RTO vs. RPO are:
Timing. This factor actually varies, but the most important thing here is to discuss this upfront with each client. The timing for RTO and RPOs is generally dependent on the client’s needs and industry. So, while RTO may be done after an event in some cases, that’s not a guarantee it is what matches a given client.
RTO and RPO both play an integral part in backup and disaster recovery. This is especially important in the current climate. The State of SMB Cybersecurity in 2022 report found the following information:
In the event of a disaster, your client’s RTO is going to indicate how long their organization experiences downtime, while RPO is a representation of how much data they can afford to lose during the event and still function. While these two metrics will go a long way toward crafting an overall disaster recovery plan, a third metric may be just as important.
An organization’s MTPD, or maximum tolerable period of disruption, is integral to your overall RTO and RPO strategy. Your client’s MTPD measures how long your clients can “keep the ship afloat” in the middle of a disaster event. Basically, how long can their people and infrastructure withstand a system outage?
What makes MTPD tricky is that this metric can vary from system to system, application to application. But, calculating this number accurately can significantly improve your RTO/RPO strategy. For example, if you know a client’s MTPD is one hour, then you know their data should be backed up every hour. Therefore, an effective RTO should be equal to or less than a client’s MTPD.
Considering all three metrics – RTO, RPO, and MTPD – puts you in the best position to protect your client’s cybersecurity center. You’ll know how long your client can withstand an outage with MTPD, how often their data should be backed up with RPO, and what resources you’ll need to allocate toward the system to achieve your desired RTO.
We hope that now you understand the differences between RTO vs. RPO. But, that’s just a tiny part of the larger puzzle that makes up proper BDR protocols. For more in-depth knowledge on how each of these concepts fits into an overall BDR plan, check out the ConnectWise cybersecurity glossary.
This resource is full of supporting concepts that will help you better understand the need for airtight, repeatable practices regarding RTO and RPO.
Share: