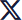High availability, or eliminating single points of failure, is a crucial aspect of any organization's IT infrastructure. It ensures that systems and services are highly available to users, even during a failure or outage. The availability is measured in “four nines” or “five nines,” which translates to 99.99% or 99.999% of uptime. In today's digital age, where businesses increasingly rely on cloud-based services, high availability has become even more important.
Why do we need high availability?
There are many situations where critical applications and platforms have faced outages due to lack of high availability. Building and running any involves careful orchestration of hundreds of thousands of subsystems and services in various operating systems and run-time environments distributed across geographical regions. Even though proactive measures are taken to ensure the platforms are resilient through various scale and performance tests, there are always corner cases. These may be tough to replicate and, in some cases, are dependent on external factors such as internet service providers, electrical subsystems, and failures in hardware, to name a few.
When a system lacks high availability, it can lead to several problems. For example, it can cause disruptions to business operations, resulting in lost productivity and revenue. It can also lead to poor customer experiences, as users may be unable to access the services they need. Additionally, it can lead to data loss or corruption, which can be costly and time-consuming to recover from.
Several factors can contribute to a lack of high availability. One of the most common is a lack of redundancy, which refers to the ability of a system to continue functioning even if one component fails. Without redundancy, a single point of failure can bring down the entire system. Another factor that can contribute to a lack of high availability is a lack of proper maintenance and monitoring, which can prevent early detection of potential problems.
It is critical to design the systems to be resilient for failures in the application/platform and as well failures that occur beyond the scope of the application/platform.
4 ways to achieve high availability
One of the key benefits of cloud computing is the ability to scale resources on demand, which means that organizations can easily add more resources to their infrastructure as needed. This is especially useful for organizations that experience sudden spikes in traffic or usage. However, it also means that organizations need to be prepared for the possibility of an outage or failure. It’s wise to use various strategies and tools for fuller coverage. Here are four best practices for high availability:
- Geographic redundancy, or deploying servers in multiple zones or regions, is one of the most common strategies. Geographically separated locations provide redundancy in case of an outage in one location. By spreading resources across multiple availability zones, organizations can ensure their systems remain available even if a location goes down.
- “Load balancing” is a technique that distributes traffic across multiple servers, ensuring that no single server is overwhelmed by traffic. This can be done using a variety of tools, such as a load balancer or a content delivery network (CDN).
- Auto-scaling is a feature that automatically adjusts the number of resources (such as servers or virtual machines) based on the current load. This ensures that resources are always available to meet demand without wasting resources on idle servers.
- Business continuity and disaster recovery (BCDR) backup solutions ensure data is protected in case of an outage or failure. This can include using snapshots, backups, or replication to ensure that data is always available, even in the event of an outage or failure.
How to balance high availability with other factors
Balancing high availability and factors like cost can be a challenging task for organizations. On the one hand, high availability is essential for ensuring that systems and services are always available to users, even in the event of an outage or failure. On the other hand, achieving high availability can be costly, as it often requires the use of additional resources, such as redundant servers and network infrastructure.
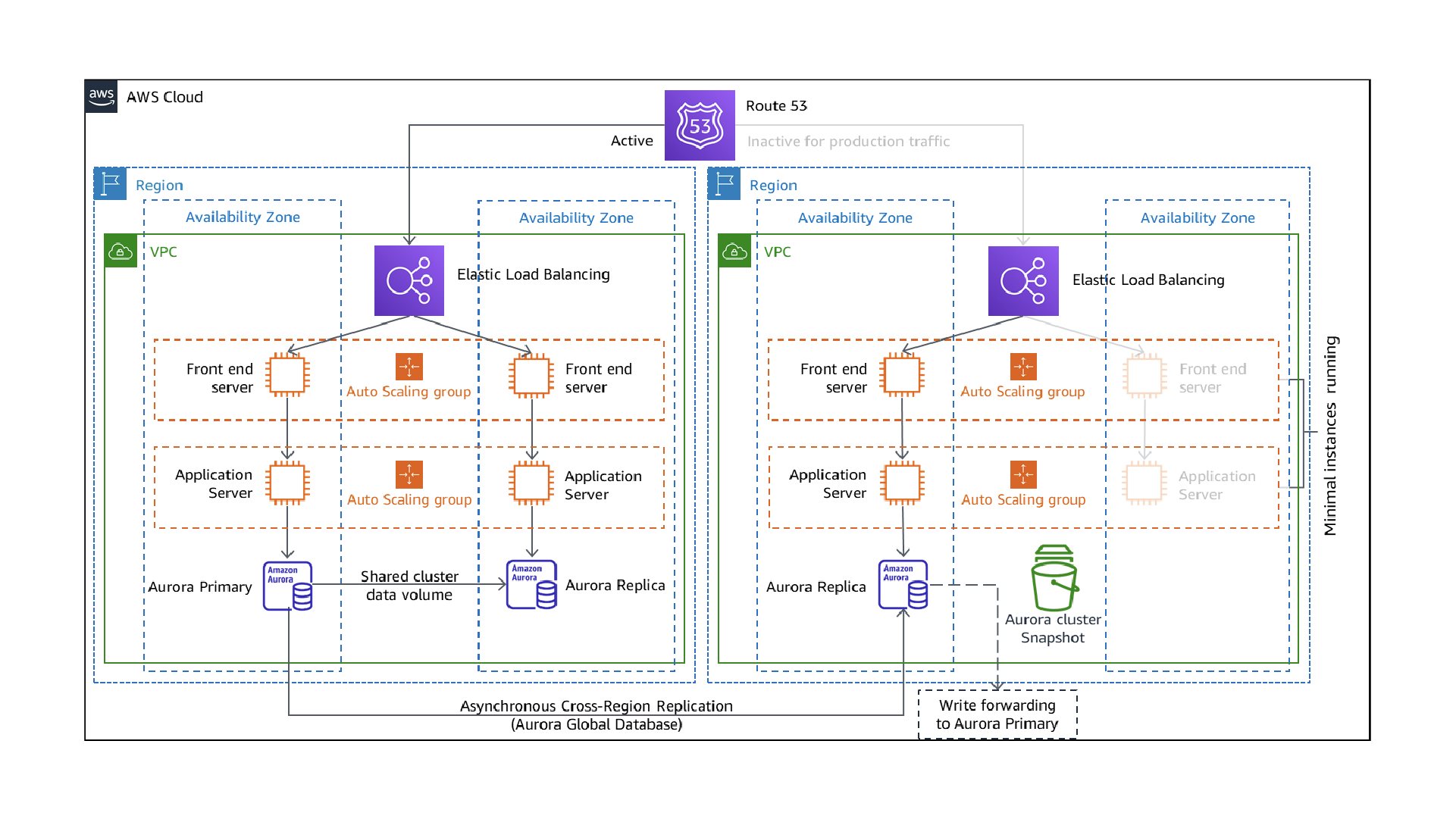
Figure 1: Depiction of high availability architecture in the AWS cloud deployment. The image describes the achievement of high availability across regions. This architecture is not just resilient to instance-level failures and availability zone failures, it can also sustain region-level failures in the cloud.
The above architecture guarantees higher availability, but it also requires more infrastructure. How do you balance high availability with cost?
Here are five strategies to balance high availability and cost:
- Prioritize critical systems: Not all systems and services are equally critical to an organization's operations. By prioritizing critical systems, organizations can focus their efforts and resources on ensuring high availability for the most important systems while accepting a lower level of availability for less critical systems.
- Use cost-effective solutions: There are a variety of solutions available for achieving high availability, and some are more cost-effective than others. For example, using multiple availability zones or regions can provide redundancy at a lower cost than using multiple data centers. Similarly, using load balancers or auto-scaling can provide high availability at a lower cost than using additional servers.
- Use cloud-based services: Cloud computing can provide a cost-effective way to achieve high availability. Cloud providers often offer built-in redundancy and automatic failover, which can reduce the cost and complexity of achieving high availability.
- Implement BCDR backup solutions: BCDR solutions can be a cost-effective way to ensure high availability. By having a disaster recovery plan in place, organizations can minimize the impact of an outage or failure and reduce the likelihood of data loss.
- Continuously monitor and evaluate: Organizations should continuously monitor and evaluate their systems and services to identify areas where they can improve high availability while reducing costs. This can include identifying and eliminating single points of failure, identifying and fixing performance bottlenecks, and identifying areas where resources can be consolidated.
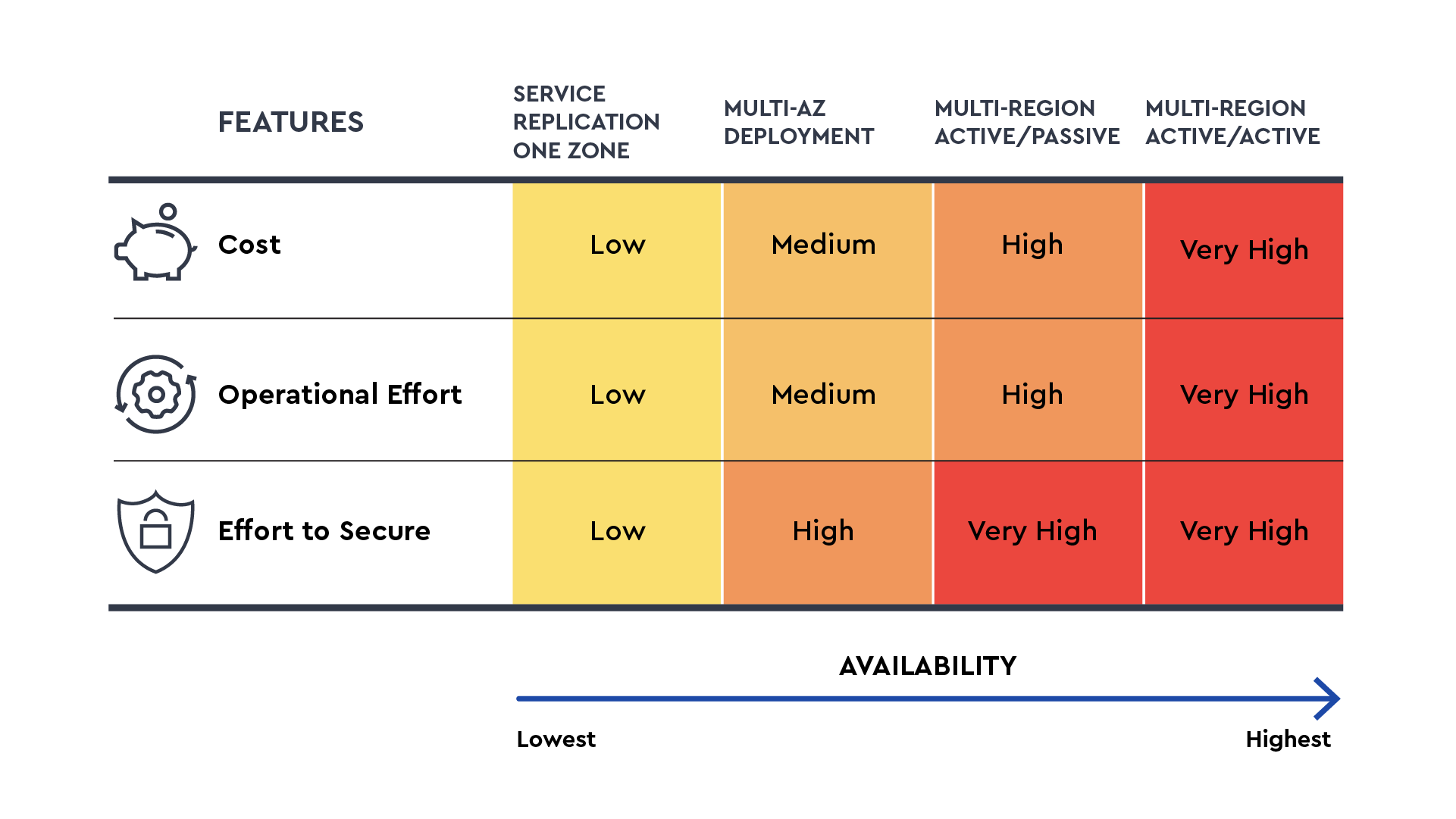
Figure 2: Depiction of factors: Cost, operational effort, and effort to secure correspond to various availability choices.
How ConnectWise achieves high availability
In the ConnectWise Asio ™ platform, high availability, resiliency, and scalability are fundamental tenets of the design and architecture of the services. We prioritize and place each service in a tier of availability based on the criticality and customer use of the services.
- We have predefined reference architectural approaches to match the tiering of the service and have built a well-architected approach that defines specific components to be used across the application stack to meet the availability needs and standards for each of the services. The tiering of a service is applied based on the impact to our partners’ experience and the sustainability of the failure. As an example, service-providing REST API is tiered higher than service-providing analytics. This allows us not to take a one-size-fits-all approach for all services and provide the highest level of availability for the services impacting partner experience.
- The infrastructure components and high availability are configured through the infrastructure as a code approach, allowing for consistency of the service behavior across various regions worldwide.
- We take advantage of managed services in cases where applicable and rely on the cloud provider to handle high availability and resiliency. These allow us to take advantage of the efforts from the cloud provider and not reinvent the wheel.
- We vet serverless managed services and self-managed services on a case-by-case basis to take advantage of configurations that provide maximum value in line with our architectural pillars.
We also rely on the industry reference architectures and blueprints where available and build upon industry best practices rather than reinvent the wheel.
Figure 3: Depiction of availability tiers in the Asio platform
TL;DR
High availability is a crucial aspect of an organization's IT infrastructure. It ensures that systems and services are available to users, even during a failure or outage, and is measured in “four nines” or “five nines” of uptime. Lack of high availability can cause disruptions to business operations, poor customer experiences, data loss or corruption, and loss of revenue. Achieving high availability in the cloud can be done using strategies such as multiple availability zones or regions, load balancing, auto-scaling, and BCDR backup solutions.
Balancing high availability and cost can be challenging for organizations, but strategies such as prioritizing critical systems, using cost-effective solutions, cloud-based services, implementing BCDR backup solutions, and continuously monitoring and evaluating systems can help organizations balance high availability and cost.