11/3/2023 | 7 Minute Read
Topics:

With the abundance of data available today, organizations have diverse options for managing and analyzing it. Four significant data management and analytics architectures are data warehouse, data lake, data lakehouse, and data mesh. Each approach has unique characteristics, use cases, and benefits. In this in-depth comparison, we will explore the details of each architecture to assist you in comprehending when and how to use them.
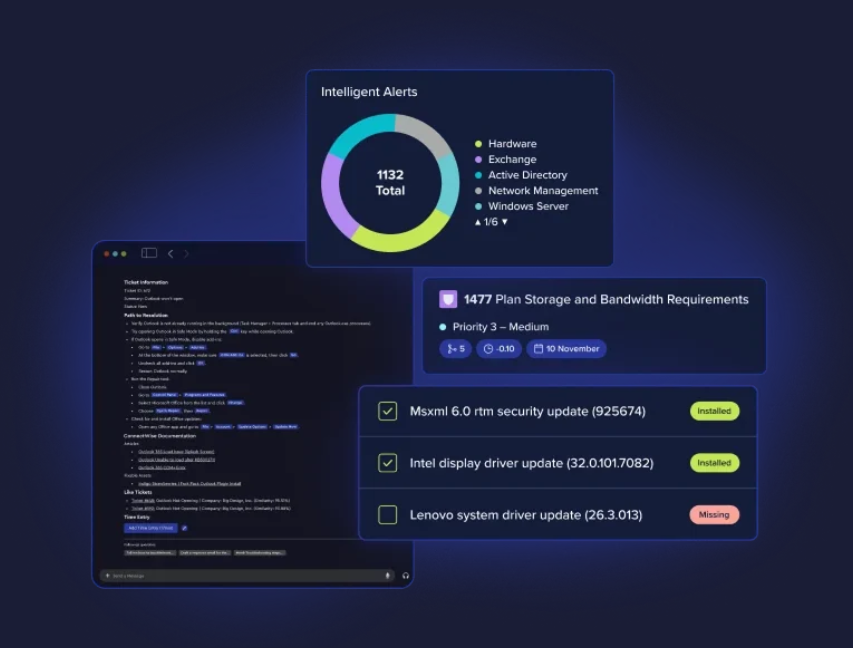
A data warehouse is a specialized database system designed for the storage, retrieval, and analysis of structured data. It serves as a central repository for an organization’s historical data, primarily focusing on structured and well-defined data sources.
As data warehouses are used to store historical data for analysis and reporting, they consolidate structured data from multiple sources and optimize query performance with techniques such as indexing and partitioning. Before ingesting the data, data warehouses use ETL procedures to structure and transform data to ensure consistency and quality.
When it comes to storing the data in a data warehouse, it’s stored in either a columnar or row-based format. Using data marts, which are subsets of data focused on specific business areas for efficient retrieval, star or snowflake schema models organize data for complex queries with multiple dimensions and measures. They also use SQL for queries and OLAP for multidimensional analysis.
Data warehouses are critical for generating reports, visualizations, and historical analysis in business intelligence. They also offer strong data governance for cybersecurity, quality, and compliance.
Data warehouses can be traditional on-premise solutions, like Oracle Exadata, IBM Db2 Warehouse, and Teradata, or they can be cloud-based solutions like Amazon Redshift, Google BigQuery, and Snowflake. Cloud data warehouses are increasingly popular due to their scalability and managed services.
On the other hand, data warehouses are expensive to build and maintain, causing delays in data processing and making them less ideal for real-time analytics. Modifying them for changes in data schemas can also be complicated and time-consuming.
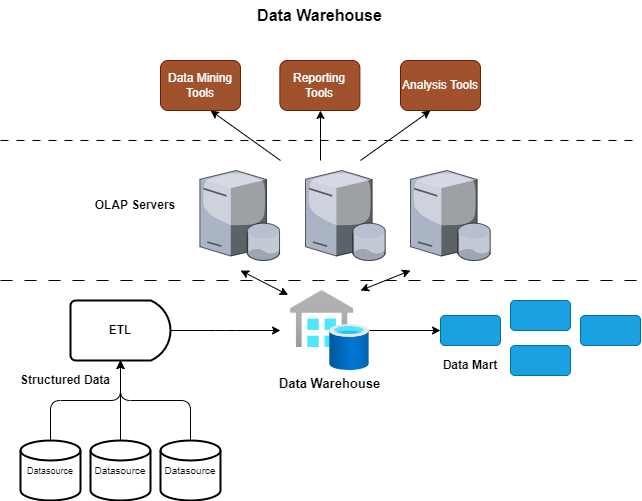
Figure 1: Data warehouse
A data lake is a central repository for storing vast amounts of raw, semi-structured, and unstructured data at scale. Unlike traditional databases, data lakes are designed to handle data in its native format without the need for prior structuring.
Data lakes store raw and untransformed data, and they’re highly scalable for big data and IoT applications. Schema-on-read allows for flexible data exploration, and they can handle large amounts of data from diverse sources using distributed file systems or cloud-based storage. Partitioning can also help to improve query performance.
Data lakes use schema-on-read to transform and structure data for analysis. Common processing frameworks, like Apache Spark, are used for data processing and analysis. Data lakes are great for machine learning and data science.
Data lakes simplify data exploration by enabling users to extract insights from raw data before structuring it. They support advanced analytics like predictive modeling, anomaly detection, and sentiment analysis, and they can be integrated with data lakehouse architectures for structured querying.
Data lakes come in two types: on-premises and cloud-based. Apache Hadoop and HDFS are often used for on-premises data lakes, while AWS Data Lake, Azure Data Lake Storage, and Google Cloud Storage are some of the more popular cloud-based options.
However, data lakes can be challenging to manage due to their high volume and diversity of data. Proper planning is necessary to avoid disorganization and poor performance when querying unstructured data.
Figure 2: Data lake
A data lakehouse is a relatively new and hybrid data architecture that aims to combine the benefits of both data lakes and data warehouses. It addresses the need for scalable storage, schema-on-read flexibility, and structured querying capabilities.
The data lakehouse approach combines the strengths of data lakes and data warehouses. It can store both structured and semi-structured data, and it uses advanced technologies, such as Delta Lake or Apache Iceberg, for schema evolution and data versioning. It often uses distributed file systems or cloud-based storage for unified storage.
Since data lakehouses handle both raw and structured data, they use ETL and ELT processes to transform and load data for analytical querying. Data lakehouses support advanced querying with SQL, making them compatible with a range of analytics tools and frameworks. Some also enable time-travel queries for historical analysis.
Data lakehouses combine data lakes and data warehouses, creating the ideal for structured analytics and raw data exploration. They’re great for data science and machine learning projects, as they have the ability to scale to meet growing data needs. Just look at Delta Lake and Apache Iceberg, which have brought ACID transactions, schema evolution, and time-travel features to big data workloads.
Data lakehouses are flexible and versatile, combining the benefits of data lakes with structured querying capabilities. This allows for diverse data usage and easy adaptation to changing data requirements. They also offer a unified storage solution for both raw and structured data, making data management simpler—which is ideal for various analytics, from basic reporting to advanced data science.
However, compared to traditional data warehouses, data lakehouse architecture requires careful planning and management, with additional overhead for ACID transactions and time-travel features. Schema-on-read and schema-on-write may also require adjustment.
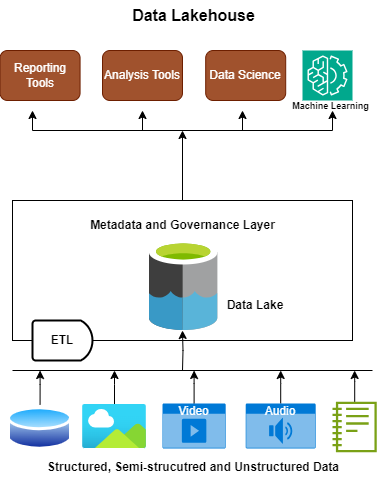
Figure 3: Data lakehouse
Data mesh is a modern data architecture and organizational approach that aims to address the challenges of scaling and democratizing data within large, complex organizations. It represents a shift away from a centralized data approach to a more decentralized, domain-oriented model.
Data mesh promotes decentralized data ownership and management across domains. It encourages cross-functional teams to treat data as a product and take responsibility for its quality and governance, creating a data fabric that facilitates data discovery, access, and sharing.
This principle helps distribute the burden of data management across the organization and allows domain experts to make data-related decisions, which can lead to better data outcomes.
Treating data as a product emphasizes the importance of quality, usability, and accountability. Data producers need to understand the needs of their data consumers and provide data in a user-friendly and accessible manner. This principle encourages data teams to focus on delivering value to the organization through their data products.
Enabling teams to access and leverage data independently through self-serve infrastructure can enhance their agility and self-sufficiency. This approach minimizes bottlenecks and delays in data access, fosters experimentation, and enables teams to iterate rapidly. This principle advances data democratization and agility within the organization.
Federated governance is a system that tailors governance policies to meet the specific needs and regulations of each domain, and this approach helps organizations find a balance between centralized control and domain autonomy. In doing so, it helps maintain the integrity of data while catering to the diverse needs of different parts of the organization.
Our data services and APIs also allow easy access to our products. Using the data mesh approach, teams can independently use the data without a centralized team. Our catalog and infrastructure promote the discoverability of relevant data products for easy access.
Data mesh is ideal for large organizations with complex data requirements. It promotes agility and faster data delivery by allowing domain teams to own and control their data, enabling quick adaptation to new requirements. Data democratization also enables more groups and individuals to access and use data according to their needs.
Data mesh implementations often use cloud-native tech, microservices, data lakes, and warehouses. This tech is perfect for complex organizations with diverse data needs, as it democratizes data access for more teams, boosts agility, and improves data quality and governance.
However, implementing a data mesh requires organizational changes like new team structures. A clear strategy and governance framework are also crucial to managing this architecture. Plus, keeping the data catalog up-to-date can be challenging in rapidly evolving organizations.
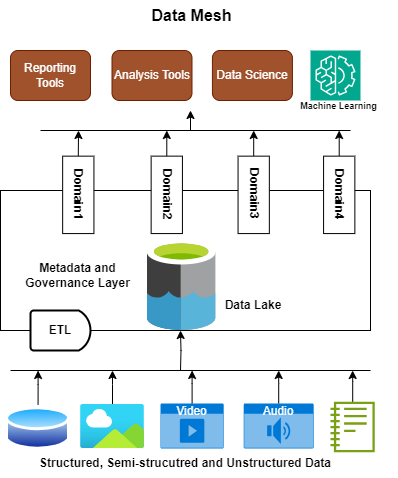
Figure 4: Data mesh
When it comes to deciding which data storage architecture is right for you, there are many factors to consider. Each architecture type can be especially useful in specific scenarios, so understanding what those are can help make that decision for you.
For example, if your data is primarily structured and you need a reliable source for reporting and BI, opt for a data warehouse. However, if you have diverse, raw, and unstructured data that requires flexibility for exploration and analysis, you may want to choose a data lake.
If you need to combine structured and raw data in a way that allows for both analytics and data science, consider a data lakehouse. And finally, if you need to address complex, decentralized data needs in a large organization that promotes agility and domain-centric ownership, a data mesh may be the architecture for you.
While this can be helpful to know, in reality, lots of organizations use a combination of different data processing and analytics architectures to suit their specific requirements. Which approach you choose will depend on your organization’s data types, intended uses, and goals. Sometimes, a mix of these architectures can offer the most complete solution for your data needs.
Share: